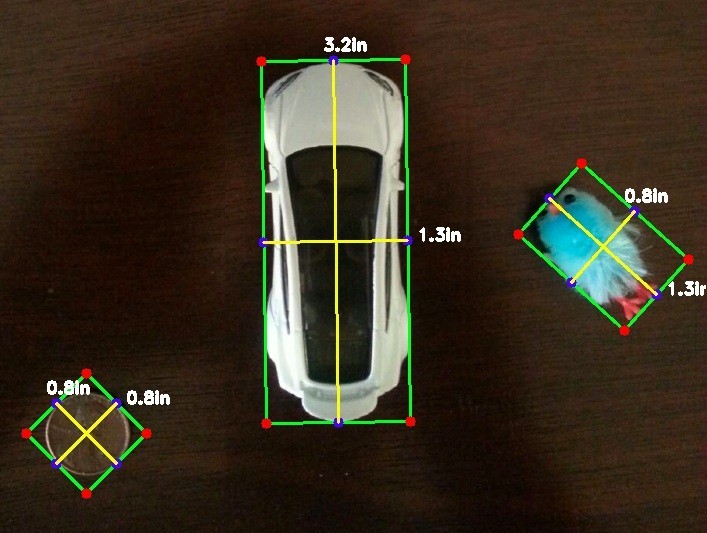
Calculating the Size of Objects in Photos with Computer Vision
Table of Contents Overview Setup Windows Linux OSX OpenCV Basics Getting Started Takeaways Overview You might have wondered how it is that your favorite social networking application can recognize you and your friends’ faces when you tag them in a photo. Maybe like Harry Potter, a mysterious letter arrived at your doorstep on your birthday; only this letter wasn’t an